1. COMPRESSION / COLLAPSE :
- Compression can be done only on Infocube.
- If we compress InfoCube all key figures data is aggregated with respect to same characteristic combination.
- Before compression data is in F Fact table, After Compression data moves to E fact Table.
- After Compression F-Fact table deleted.
- Compression reduces Data Manager read time & OLAP Aggregation Time.
- If we compress InfoCube Request wise data is removed , even we cant delete request wise data.
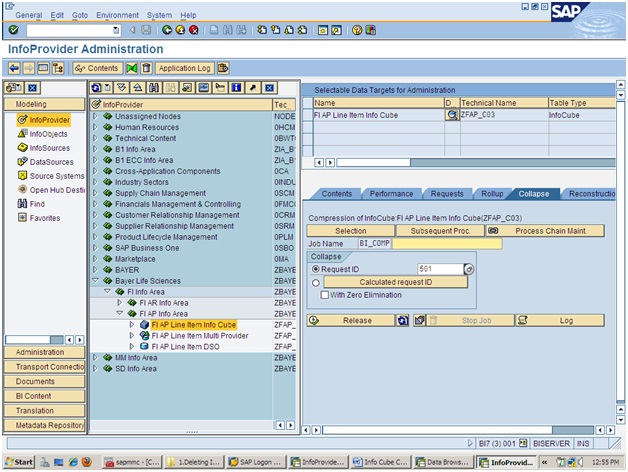
Steps to Create Compression:
- Tcode RSA1 ----> Select Required Info cube ----> Right Click ----> Manage
If i compress any latest request all the older request also compressed. - Go to Collapse Tab ----> Request ID (select the latest request) ----> select flag for with ZZero Elimination.
With 0 elimination ----> During compression if all key figure values are 0 , Then storing that record is unnecessary , to remove the records from Infocube --- use this flag. - Click on Release ----> Select No ----> Go to Contents.
- Enter table Names F & E ----------->EX.. /BIC/FZTAB_C01
2. AGGREGATES :
- Aggregates are "Baby Cubes" which contains InfoCube Like Structure.
- Example :
Country / Region / Sales
us / central / 1200
us / Estern / 2000
IND / south / 2200
IND / north / 2000
Query on Country and sales
Data Manager ---- 4 records.
us ---- 2 records ----> Aggregated to 1 record.
IND ---- 2 records ----> Aggregated to 1 record
Aggregate With Respect to Country
Country / sales
US / 3200
IND / 4200
Query -----> Data Manager ---2 / OLAP ---0
NOTE : If you want to Know Data Manager and OLAP and all see this : http://learnsapbi.weebly.com/sap-bi/performance-supporting-jobs-in-sap-bi - Aggregate reduces Data Manager read time and OLAP Aggregation time by reducing the No.of records and by aggregating all the key figures with respect to the characteristic , the Aggregate is created.
- When you run the query , first it loads for aggregate , if it finds enough data with aggregate , it does't find again it reads data from InfoCube.
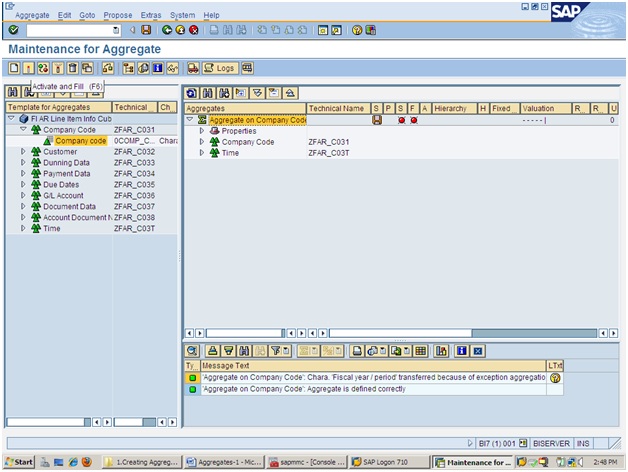
Types of Aggregates :
- Aggregate by all values of chars : W.r.t all the vales of a characteristic the data is aggregated.
- Aggregate by a Fixed Value of characteristic : W.r.t a single vale of the char the data is aggregated.
- Aggregate by Hierarchy level : w.r.t a level of the hierarchy the data is ggregated, here all the lower level nodes is aggregated and stored as upper mode.
3. ROLL UP
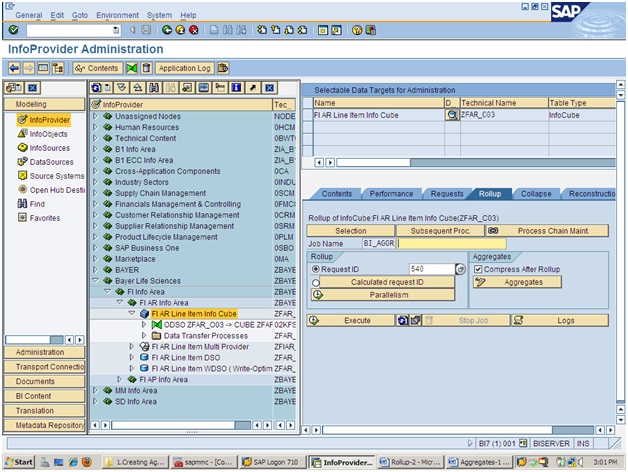
- Loading Data form InfoCube to aggregate , without Roll Up , the new request is not available for reporting.
- Before compression do the Roll Up , Because compression eliminates the request , but the roll-up is request wise.
4. PARTITIONING AND RE PARTITIONING :
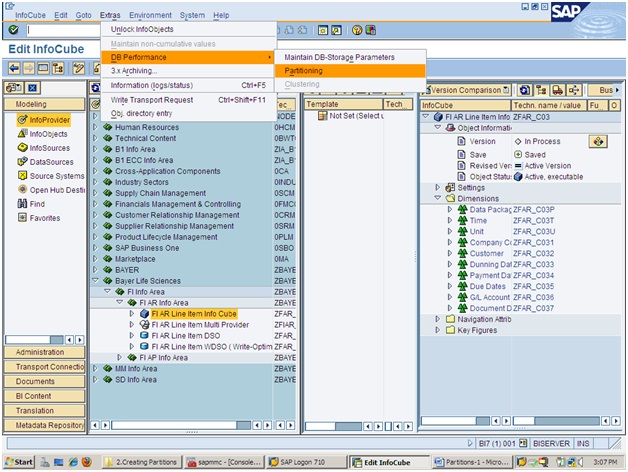
EX. In one Infocube contains ----> 2001 to 2015 data .
Query ----> Read 2010 data if has to read all the 15years data with is unnecessary
calyear / month ----> Partitioning -----> 12 months -----> make one Partition
Precautions While Doing Partitioning :
 RSS Feed
RSS Feed
